- Published on
Why Finetune Code LLMs for your Codebase?
- Authors

- Name
- CGFT Engineering
Finetuning Code LLMs for your Codebase
TL;DR
Today’s code LLMs fall short when it comes to complex, enterprise-grade codebases. They struggle to grasp an internal codebase’s unique patterns, frameworks & business logic. This results in subpar code AI experiences across the SDLC e.g. test generation, review automation, code generation, etc.
We’re solving this by fine-tuning models specifically on an enterprise’s internal engineering data - tapping into resources like documentation, tests, code reviews, and commit histories. Our fine-tuning pipelines already show impressive results across multiple product experiences: boosting performance by ~50% for both Github Copilot-style code completion and next edit prediction when compared to models like Starcoder2, DeepSeek-Coder and GPT-4o.
Reach out to us at ft@cgft.io if your team wants code AI experiences custom built for your internal dev environment — especially if you're working with iOS/Android, legacy code or newer languages like Rust.
Why Repo-Specific Finetuning?
Even the smartest staff engineers aren't instantly productive when working with a new codebase. They need time to get up to speed — reading codebases and documentation to familiarize with shared frameworks, patterns and business logic.
Code LLMs need a similar onboarding process. Fine-tuning enables this onboarding for code LLMs for tasks across the SDLC
- Test Generation & Debugging → Fine-tuning enables models to reason about code execution and semantics around business logic in your environment.
- Code Review Automation → Fine-tuning imbues models with architectural/stylistic patterns to follow and anti-patterns to avoid
- Code Completion → Fine-tuning enables models to generate code that follows internal patterns and composes nicely with existing abstractions.
Why not just prompt?
A common debate in LLM land lately has been whether it's better to fine-tune models or simply prompt them with relevant context. For code AI, this involves retrieving relevant code snippets from the broader codebase. We believe prompting with context is useful & necessary, but insufficient. Fine-tuning enables models to more effectively reason over and utilize the context provided in a prompt.
Additionally, fine-tuning helps bridge data distribution differences between the model's pre-training and inference phases.
Data Distribution
Models are fundamentally a product of the data they’re trained on. For code LLMs, that data is public open-source repositories on platforms like GitHub. Many of these repositories are typically hobbyist projects. The more complex, enterprise-grade open-source repos skew towards developer frameworks (like PyTorch or Grafana) or packages on platforms like pip or npm.
This is quite different from most closed-source repositories which tend to live in the application layer (think Snapchat’s mobile app or Notion’s backend services). Given the differences in data distribution, fine-tuning enables models to better model the distribution of the code repository they’re going to be used with.
Open Weights Models Have Become Really Good
Up till recently, prompting has generally been preferred to fine-tuning due to a significant performance gap between closed-weight models and their open-weight counterparts. It has also been easier to interact with closed-weight models through prompting since fine-tuning APIs tend to be algorithmically restrictive.
That gap has since closed. Models such as DeepSeekCoder and Starcoder are used widely by devs through tools such as Cody, Continue.dev. Many find these open-weight models to be on par with, or even superior to, their closed-source alternatives.
Given this progress, we believe that codebase-specific fine-tuning on open-weight LLMs can deliver significantly better code generation experiences compared to both general-purpose closed-weights and open-weights models.
The Richness of Internal Data
To fine-tune effectively, you need substantial amounts of high-quality data. Enterprises do have such rich internal engineering data. These data points can offer valuable signals to enhance a code LLM’s performance on tasks across the software development lifecycle.
Here are some we’re particularly excited about:
Conversations and Documentation around Code
Slack conversations, internal documentation, and production incident post-mortems can give models a deeper semantic understanding of code and architecture. This enables better chat-with-code experiences at the right abstraction level.
Tests
Enterprise codebases tend to have decent test coverage which can be used for richer feedback during model training → ensuring the code generated by the model passes tests vs simply minimizing next token loss. Existing function ↔ unit test pairs can also be used to train the model on test-generation.
Review Comments
Code review comments and the associated changes offer insights into internal development patterns that the generated code should follow. This helps the model adhere to & enforce established internal coding standards and practices in reviews.
Commits
Most training pipelines model codebases as static lists of files that were written from scratch, one token at a time. But, codebases are effectively a time series of commits over time. With commit histories, you can train the model to mimic an “engineer” developing the codebase progressively, one diff at a time.
A Sneak Peak - Code Completion
We utilized our fine-tuning pipeline to build out a repo-specific code completion engine (similar to Github Copilot). We benchmarked our model’s performance against the DeepSeek-Coder and Starcoder (base models that power popular code-completion tools like Cody & Continue.dev).
We first fine-tuned on the first 80% of commits in the repository. We then evaluated the model on the remaining, most recent 20% commits that were not seen during training. To provide more context to the models, we did a BM25 retrieval of relevant code blocks (functions, classes, etc.) from the repository state at commit.
We applied our pipeline to Signal’s open-source iOS and Android repositories, which are complex code-bases powering real-world applications. Below we report exact match scores - reflecting the fraction of times the model's suggested code exactly matched the actual code written by the developer in the commit.
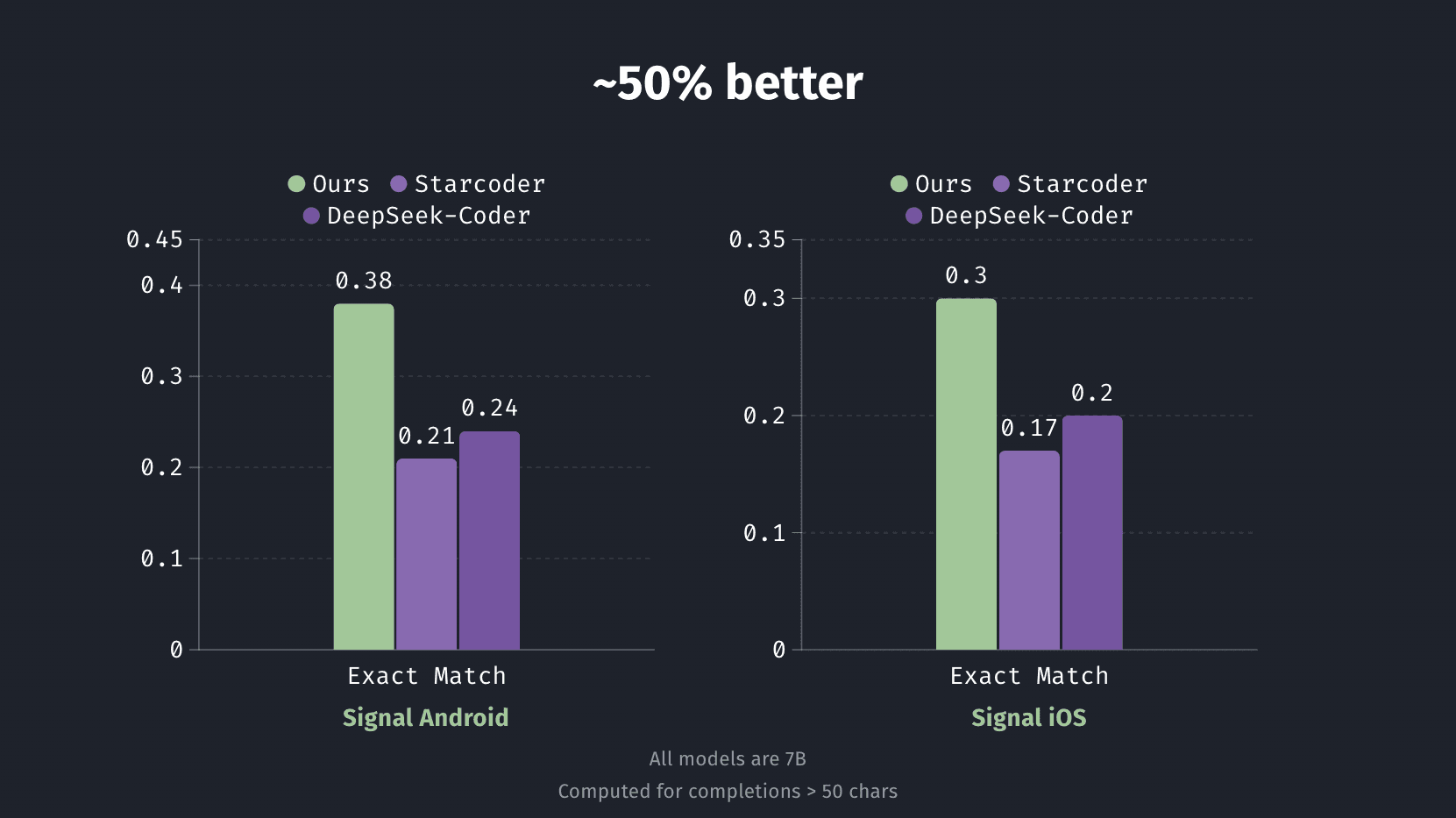
We see pretty significant ~50% gains across both repositories and metrics. The fine-tuned model does ~50% better for Android and iOS. This means significantly improved code suggestions, often matching exactly what developers intended to write and internal developer patterns.
To get more technical deets on our pipeline, head over here.
Your Turn?
Leveraging our fine-tuning on open-source repos (i.e. Signal) has already shown impressive gains. We anticipate even greater improvements for closed-source repositories not included in public training datasets.
Reach out to us at ft@cgft.io if your team wants code AI experiences custom built for your internal code, patterns and frameworks — especially if you're working with iOS/Android, legacy code or newer languages like Rust.
We're excited to explore how repo-specific fine-tuning could transform your SDLC.