- Published on
Improving Code Completion LLMs with Repo-Specific Finetuning
- Authors

- Name
- CGFT Engineering
TL;DR
At CGFT, we help enterprises fine-tune code LLMs on their internal code bases & engineering data sources. This enables more performant code AI experiences that better align with internal dev patterns & frameworks.
We're kicking off a series of posts to give you an inside look at the fine-tuning pipelines that power our product experiences. First up: good old Github Copilot-style code completion, where our pipeline yields ~50% in relative performance gains.
Data Model
For training pipelines, data quality and representation can make all the difference in a model's performance. Code completion models are typically trained using an autoregressive approach; the task is to predict the next token in a sequence of tokens, given previous tokens. But here’s the catch - this approach treats codebases as just static lists of files at their final commit state, ignoring commit history. This approach can overlook important context and the evolution of the codebase, which is useful for making more accurate and helpful code predictions.
We model codebases a little differently.
Code-Bases as Graphs

At their core, code bases are collections of code objects (functions, classes, etc.) interconnected through various relationships (inheritances, caller-callee, etc.). So, instead of treating code as just text blobs, we parse every file in a repository into code objects and map out the relationships between them. This is achieved using Language Servers, the same tech that powers features like “go-to-definition” in modern IDEs. This approach allows us to capture the graphical structure of codebases, providing richer context.
Code-Bases as Time-Series
Codebases aren't just static lists of files—they're a dynamic time series of commits. We take these commits and map each patch to the code objects we've parsed, creating a time series of code graphs corresponding to each commit.
Our data model allows us to effectively fine-tune models in a way that simulates a developer's journey from a blank slate to a constantly evolving codebase, one diff at a time. This manifests in two key ways: the sampling of target completions and the selection of relevant context for prompting.
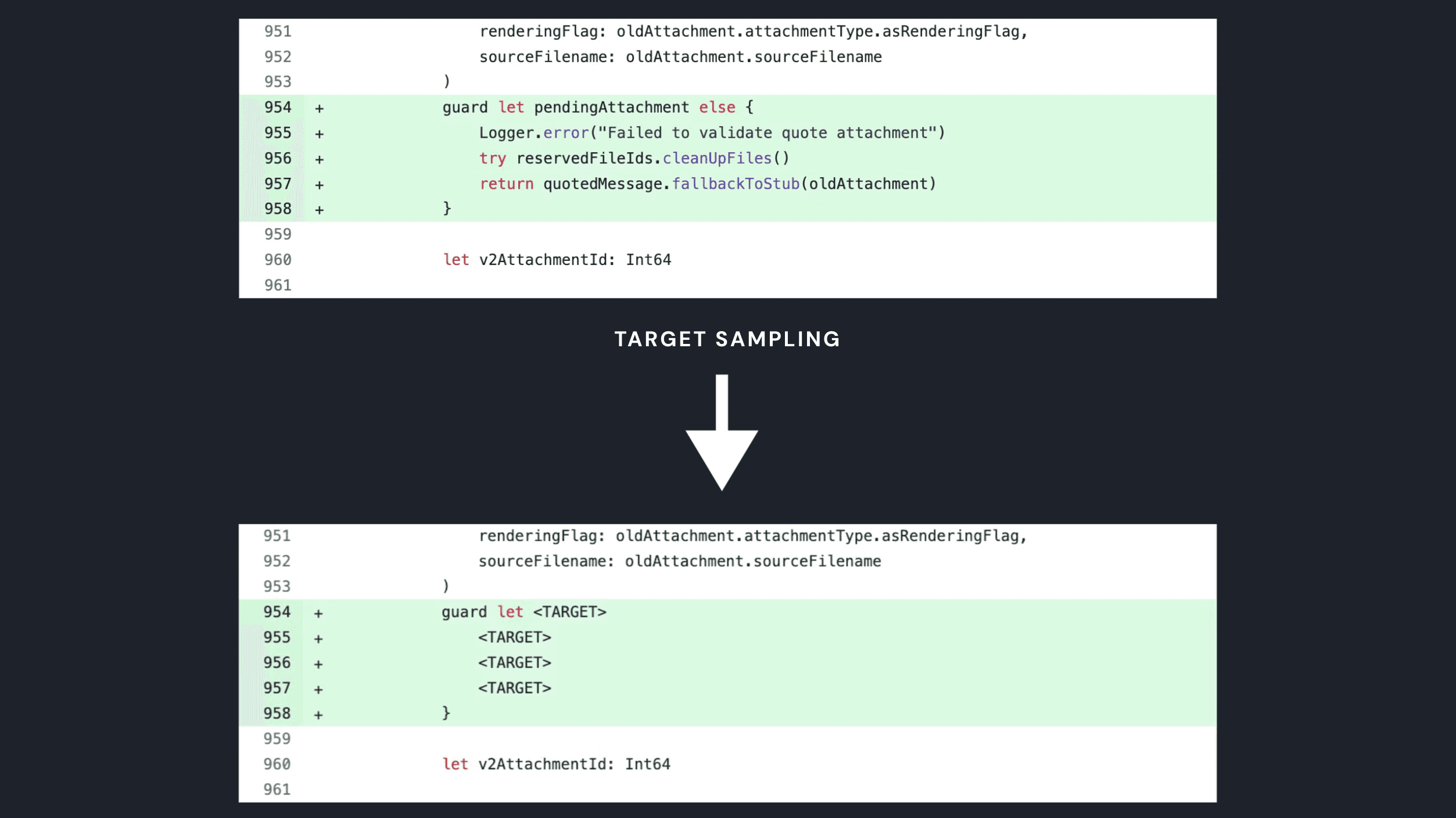
Sampling Target Completions
The fine-tuned model should learn to generate completions that align with actual changes made by devs. To achieve this, we train the model by sampling a subset of lines added in each diff within a commit, using these lines as targets for the model to predict.
Here’s what that looks like:
Prompting with (Timely) Context
Our data model also influences how we prompt the model with relevant context from the broader codebase and commits. As we mentioned in our introductory blog post, we believe that you ought to both fine-tune models AND ensure prompts have relevant context to maximize performance.
Edit Trajectories
When a developer writes or edits code, it's usually part of a larger flow of ongoing changes, rather than an isolated task. Our data model already captures this context by breaking a commit into multiple diffs across code objects. We hence sample a subset of these diffs & add them to the prompt, simulating the previous edits the developer might have made. This “mimics” the experience of a developer amid a series of edits.
Timely BM-25 Context
Cross-file context can provide useful hints to the model (function signatures, etc.) for more accurate completions. Since we maintain a time series of code graphs, we can perform BM25 retrieval across all the code blocks at the relevant commit. This ensures accurate, timely context as opposed to the flawed alternative of retrieving code blocks from the final state of the codebase. Timeliness is important as definitions and signatures can change over time, so we want to avoid introducing invalid information.
Initial Evals
For benchmarking, we applied our pipeline to Signal’s open-source iOS and Android repositories, which are complex code bases powering real-world applications with a rich commit history. With the above data model and prompting techniques, we do a LoRA fine-tune of DeepSeekCoder-6.7B (with all the good stuff including Flash-Attention-2 to speed things up). Specifically, we train on the first 80% of commits and evaluate target completions of more than 50 characters sampled from the most recent 20% of commits.
We use exact match as our metric: measuring the fraction of times the model's suggested code exactly matches the actual code written by the developer in the commit. We benchmark our fine-tunes against two baseline models: Base DeepSeekCoder-6.7B and Starcoder2-7B. These models power popular code-completion tools like Cody & Continue.dev.
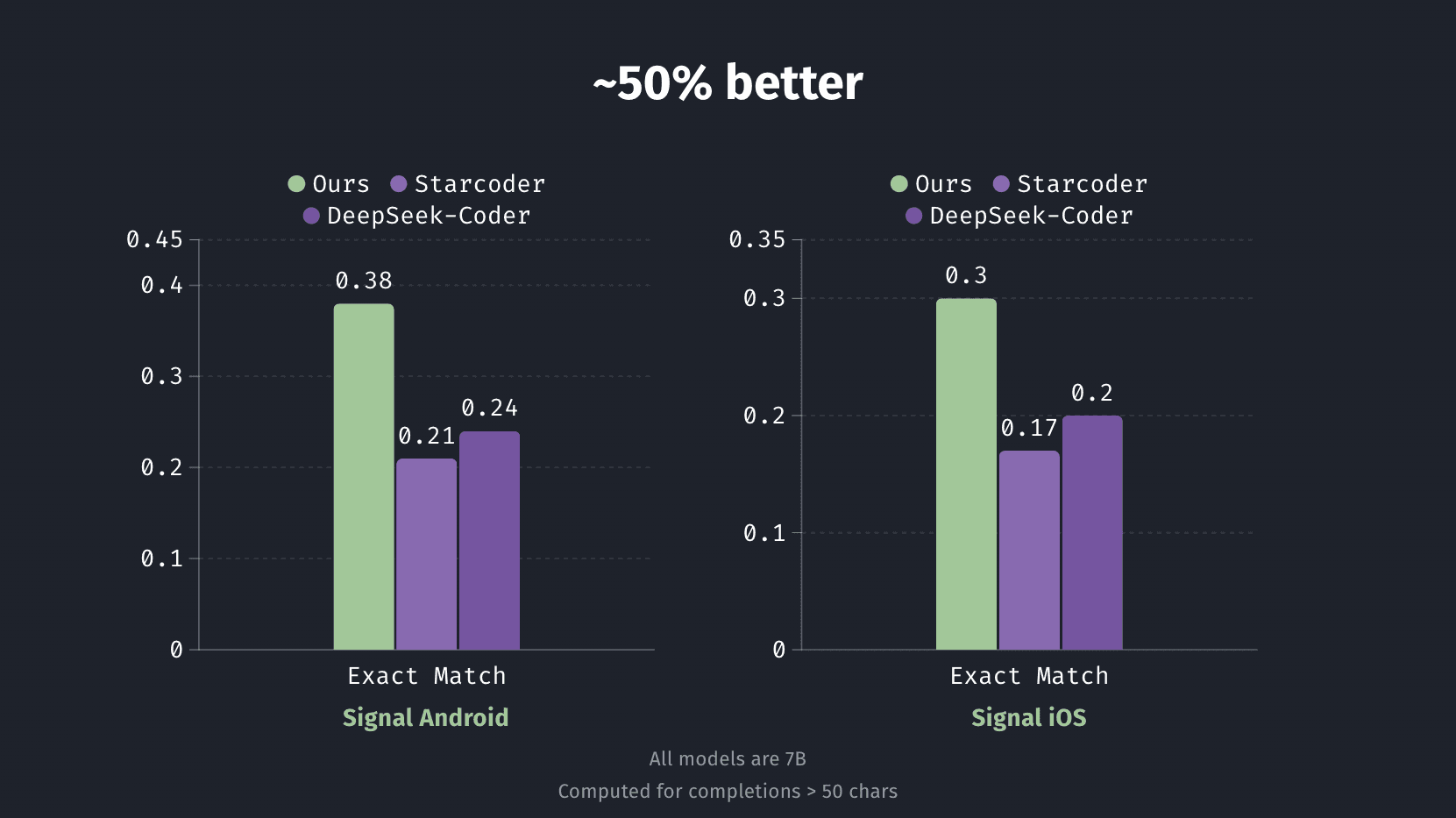
Metrics are computed for completions > 50 characters.
Our fine-tuned models demonstrate significant improvements: with gains of about 50%. This means significantly improved code suggestions, often matching exactly what developers intended to write and internal developer patterns.
Stay Tuned
We’re thrilled by the significant performance improvements we’re seeing with codebase-specific fine-tuning. Even more so, we’re still scratching the surface of what’s possible and there's so much more to come. Keep an eye out for the exciting developments we're working on!
If your team wants better code AI experiences on your internal codebase—especially if you're working with newer languages like Rust, with iOS/Android, or with legacy code — reach out to us at ft@cgft.io