- Published on
On Coding Benchmarks: Thoughts on SWE-Bench & Why Evals are Hard
- Authors

- Name
- CGFT Engineering
TL;DR
We recently came across a paper by Aleithan et al. that highlighted gaps with the SWE-Bench benchmark. The authors point to issues around solution leakage, weak tests and dataset contamination since many of the tasks are before training cutoffs of most frontier models. After correcting these issues, they observe the performance of SWE-Agent + GPT-4 dropping from 12.47% to 3.97%.
We decided to take a closer look at SWE-Bench, using it as a thought exercise to refine our internal approach to evaluating coding LLMs.
This post is not intended as a dig on SWE-Bench. It's much easier to poke holes than to build :). SWE-Bench has driven and will continue to drive immense value to codegen work. The intention here is to highlight some of the gaps in this benchmark, illustrate why evals are just fricking hard, and look beyond the headline metrics.
Overview
SWE-Bench has emerged as the standard for tracking progress of coding LLMs. It’s been thrilling to see the surge of coding agents on our Twitter feeds rapidly hill-climbing this benchmark. And clearly, agents seem to be getting really good, really fast.
While hill-climbing SWE-Bench is incredibly valuable for tracking & driving progress, one often neglects to ask exactly what hill one’s climbing. In this post, we probe into some gaps around SWE-Bench.
What is SWE-Bench?
- A dataset of 2,294 tasks crawled from public Github issues and PRs from 12 Python repos. (e.g. django, requests, etc.). The goal for the evaluated agent/system is to produce a solution patch for each task.
- Each task consists of the following:
- Problem statement describing the issue
- Commit of codebase before the issue’s resolved
- A set of tests to evaluate the patch produced by the model
- "Fail to pass" tests that fail before the solution patch is applied and should pass after
- "Pass to pass" tests to ensure there are no regressions from the suggested patch.
- Here’s an example of a task

Subtle Flaws in SWE-Bench
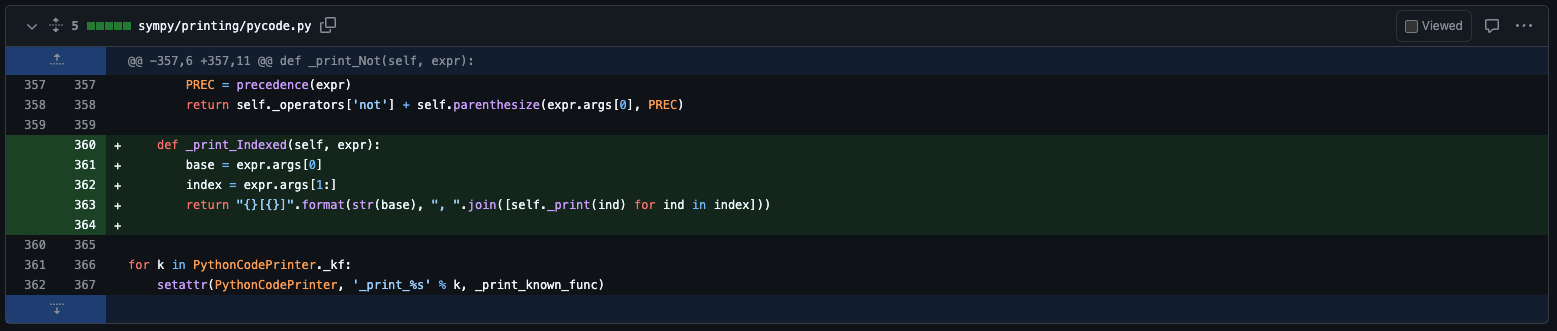
In the recent ICLR submission by SWE-Bench+: Enhanced Coding Benchmark for LLMs, Aleithan et al. manually reviewed SWE-Bench tasks which the SWE-Agent + GPT-4 system successfully solved. They uncovered subtle problems that result in SWE-Agent’s performance dropping from 12.47% to 3.97%. These issues were:
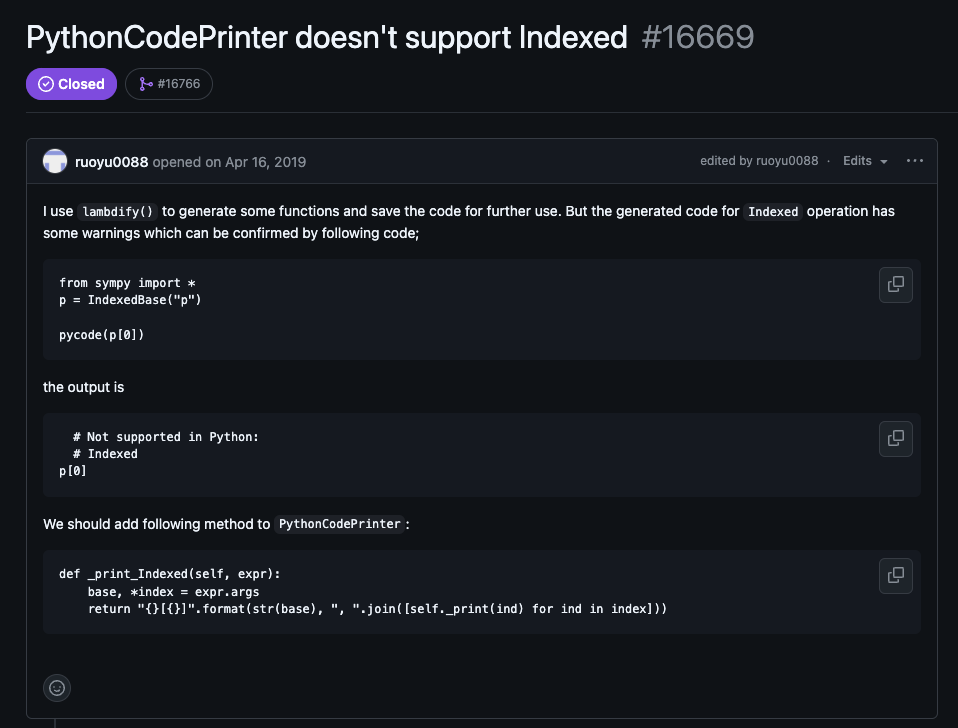
32.67% of tasks solved by SWE-Agent + GPT-4 had solutions directly provided in the issue report & PR comments. Here’s an example, where the code for the fix is verbatim in the issue text.
31.08% of tasks solved by SWE-Agent + GPT-4 were accompanied by weak test cases that were not rigorous enough. Here’s an example from the paper where the generated test passed according to the SWE-Bench harness, but isn’t quite the same execution logic.

Once the authors filtered tasks with the above two issues, they found that SWE-Agent’s performance dropped from 12.47% to 3.97%.
Another major issue with SWE-Bench is that it includes publicly available GitHub PRs and issues from 2016-2023. This predates the training cutoff for GPT and Claude, making it likely part of the training data for most frontier LLMs. The authors hence proceeded to construct a new, different dataset called SWE-Bench+, with Github issues only after the training cutoff of models and without the other mentioned issues. They report performance dropping to 0.55% - a 20x drop from 12.47%.
Framework vs. Application Layer Code
Different codebases come with distinct challenges. SWE-Bench consists of only open-source repositories in Python and are all developer frameworks e.g. Django, matplotlib, etc. While this isn’t a flaw, it is a skew toward framework-level code versus application-layer code. Think Snapchat’s iOS app or Github’s backend micro-services. Arguably, most developers today work on application-layer software vs developer frameworks.
While code is code, application layer codebases are often structured differently from developer frameworks.
Application code typically revolves around custom, specific business logic (e.g. managing subscription billing for a meal kit app). In contrast, developer frameworks prioritize extensibility for many use cases without being tied to any specific business context. These differences influence the structure and architecture of the codebases. Application codebases also tend to be structured around business domains (e.g., products, customers, orders). Backends tend to be architected as distinct micro-services consuming and producing data for each other. Frontend components tend to be structured through both visual/business logic.
This has implications when it comes to resolving issues. Issues/features for applications tend to center more around product usage, which adds to the problem of issue replication. Engineers know the struggle of reproducing a bug from a customer ticket. Tracing execution paths and understanding the architecture based solely on user experience or business logic can be quite difficult.
Different Repos, Variable Performance
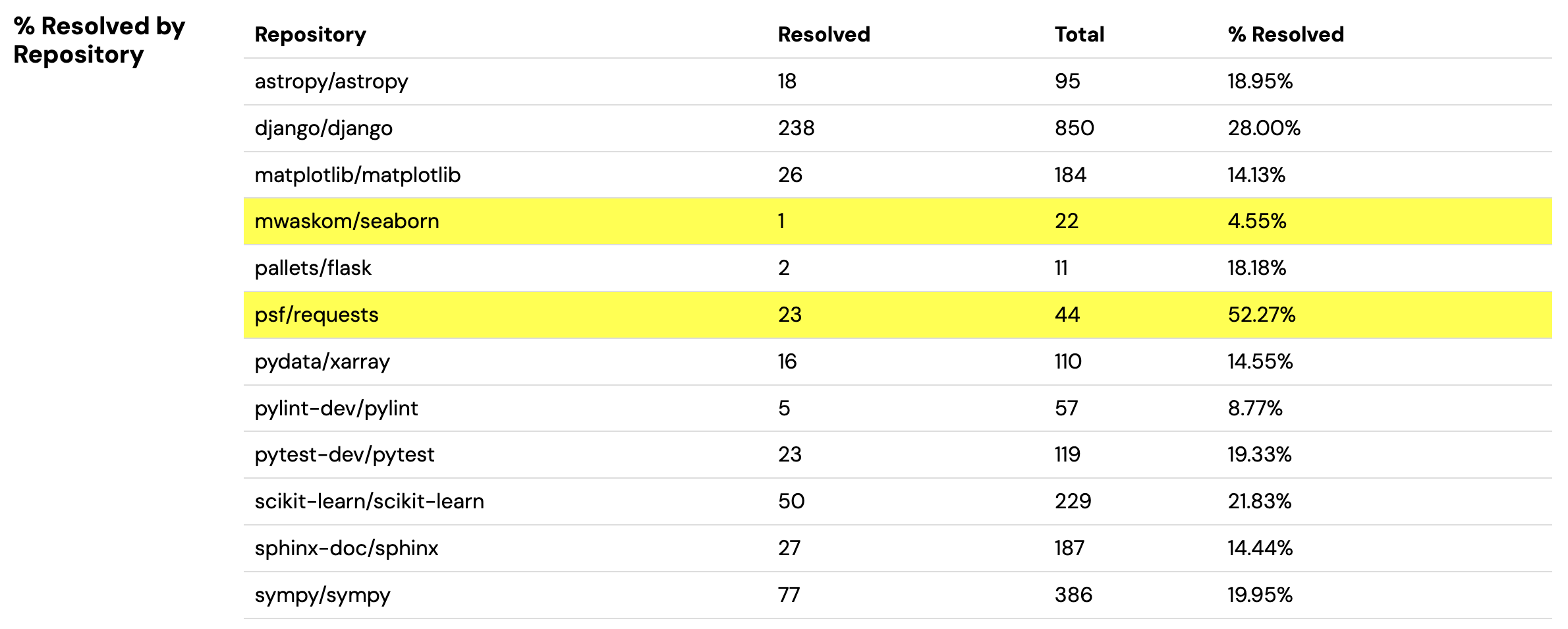
Since different types of repositories have different sorts of issues that come up, it’s natural to see performance variances. We observe this in SWE-Bench. For instance, Honeycomb (the best agent on SWE-Bench lite as of 10/26/24), has resolution rates varying from 4.55% (mwaskom/seaborn) to 52.27% (psf/requests). A 10x difference.
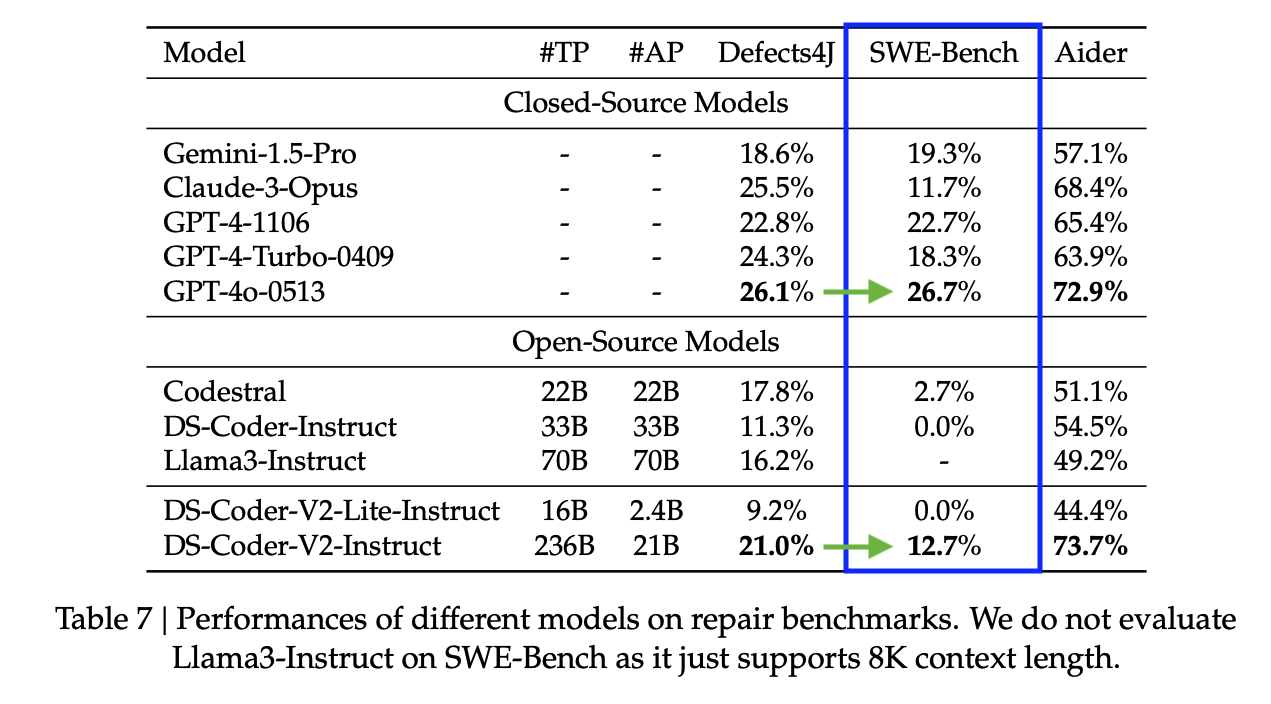
To illustrate another example, Zen & Huang et al. built a SWE-bench-like dataset for Java, which included repos like google/gson. First of all, we see that agents generally perform worse on these Java repos vs the Python ones on regular SWE-Bench.

What is even more interesting is the relative performance of LLMs. In the table above, we see agents based on DeepSeek-Coder-V2 doing better than the other LLMs on SWE-bench-java. This is not the case for Python SWE-Bench, where DeepSeek-Coder-V2 is behind the GPT-4 series as in the table below.
Everyone’s Codebase is a Special Snowflake
Given how the relative performance of systems varies based on the repository being considered, it’s crucial to consider metrics on your specific codebase. Ultimately, every codebase is unique, with its architecture, nuances, and business logic.
So, if you’re an engineering team looking to implement code AI solutions, your goal shouldn’t be optimizing for SWE-Bench/general purpose benchmarks but optimizing for your code repos. The goal’s to have a model/system that performs exceptionally well on your unique codebase, not one that ranks highly on generic tests.
That's why we're developing repo-specific evaluation pipelines to optimize the right metrics for the right tasks for a given set of repositories. And building systems to fine-tune models to excel on those metrics.
Reach out to us at ft@cgft.io if your team wants code AI experiences custom-built for your internal code, patterns, and frameworks — especially if you're working with iOS/Android, legacy code, or newer languages like Rust.